Reducing variation in credit risk-weighted assets
Reducing variation in credit risk-weighted assets - The benign and vicious cycles of internal risk models
March 2016 wasn’t a good month for so called internal risk models, the quantitative tools constructed by banks for determining such vital numbers as how much buffer capital is needed to protect the savings of their clients.
First came the Basel Committee’s proposed revision to the operational risk capital framework applicable to banks, next came a similarly fundamental overhaul of what form of risk quantification will be acceptable for calculating credit risk capital requirements.
These proposed amendments did not come as thunder out of blue skies but are the culmination of the long-running Basel III regulatory consistency assessment programme. In turn this was precipitated as a necessary, post-crisis, forensic evaluation exercise. The RCAP conclusions are basically a polite and technocratic way to state that
internal risk methodologies of regulated banks are all over the place.
This is a remarkable turnaround of fortunes. Risk quantification was all the rage around the end of the 20th century and was underpinning both the regulatory reforms that came to be known as Basel II and the rapid expansion of various new forms of financial activity.
After what seems like an enormously long time of introspection, the current consensus conclusion of regulatory bodies appears to be that
the effectiveness of internal risk identification is inversely proportional to the sophistication of the methodologies involved.
Just like the hapless IT department that released a new version of mission-critical software only to see the whole business operation collapse due to buggy features not captured in testing, regulators are now trying to revert to the last known good version.
Except there isn’t one. So they must settle for some made-up combination of old and new pieces that can be put together in a reasonable time (given also the seven year procrastination)
This regression happens at a time when information technologies elsewhere do indeed eat the world. Even after massively discounting the self-serving hype of venture capitalists, it strikes as a bit odd having ended up, A.D 2016, in a veritably neo-Luddite situation: Namely that
the capital structure of banking colossi, that directly or indirectly finance the entire global economy, is reduced to rules of thumb that can be scribbled on a napkin
How did this happen?
It invariably starts with good intentions.
Turn-of-the-century banking (+/- a few years, depending on which part of the industry and the world we are talking about) was brimming with the possibilities of information technology. Innovative database technologies (e.g., SQL), machine learning algorithms (e.g., logistic regression) and powerful new GUI’s (e.g., MS Excel) promised to transform financial risk management.
Today these same tools are the epitome of outdated, yet the categories are all exactly the same! Instead of single pages of subjective risk analysis, risk models promised to produce informed and consistent assessments of risk without biases or blind spots. It worked reasonably well in many areas! Which led to a benign cycle of ever expanded use:
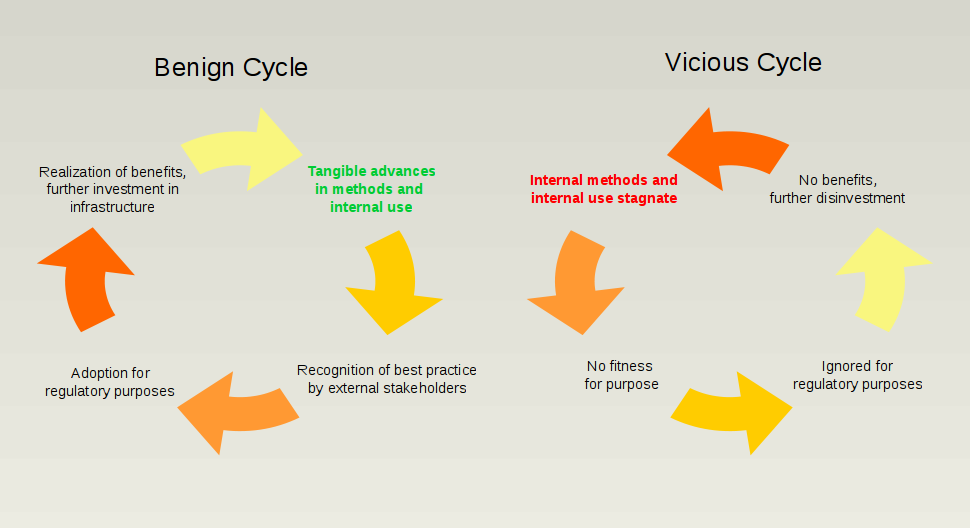
The benign cycle
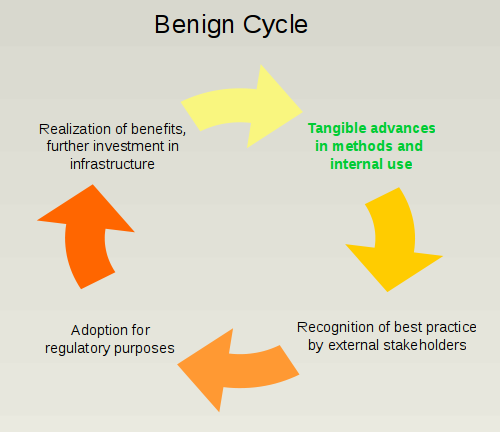
It wasn’t really surprising that employing information technology was successful in risk management applications. The economy is big and complex. Banks provide a massive leverage layer across the entire spectrum of activity. Keeping track of what is happening requires effective capture and interpretation of commensurately massive amounts of data. That’s just the reality of the thing.
This natural fit of information technology and quantification with Risk Management led to a benign cycle of internal use and external recognition. Most importantly, in the form of lower capital requirements. The motto (pertaining to risk capital buffers) was
smart is lean and dumb is fat
But things got out of hand with the capital buffer anorexia. The overall framework did not survive the financial crisis and its aftermath. Internal quantitative risk identification got tarnished alongside the extent and diversity of other risk management failures.
It is not for this piece to make a list of all the reasons why this happened. Indicatively, two very important reasons:
- Little intrinsic interest (buy-in) into the whole data+models approach by the top of the traditional bank management pyramid. Which means that once compliance / regulatory benefits were booked there was significantly less pressure to keep improving
- Severe teething problems in many areas: too much bogus academic theory, too little internal and external challenge. Which means that glaring methodology problems perpetuated instead of being addressed
Enter the vicious cycle
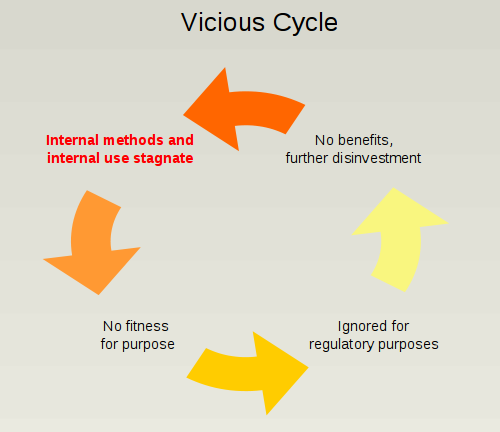
This failure brought us to today’s global risk identification dumbing-down which, together with the raising of capital buffers seems to be best captured in a new regulatory motto:
better dumb and safe than sharp and sorry
Yet without the prospect of any tangible benefit, the vicious cycle of disinvestment in internal risk models will only amplify, reinforced as it is by an environment of de-leveraging, low profitability and cost cutting.
Ironically, the mantle of data gathering and risk quantification prowess is being picked up by the unregulated sector (aka #fintech). This takes cares of Problem 1, namely provides new leaderships that are tech-native rather than techno-phobic.
But it remains to be seen if the current fintech model can scale to any significance. Namely the prevailing fintech modality of using and hyping proprietary risk quantification tools still suffers from Problem 2: lacking an environment that will foster real progress. Not having implicit government support and other disincentives may indeed induce fintech companies to pursue more rigorous internal challenge. But the magnitude of the task of fixing the wide range of required risk quantification methodologies should not be underestimated.
If we are right, the art and science of risk quantification will simply not advance unless it adopts a more open approach, embracing open source and open data